北京大学与evlo创新团队共同提出面向自动驾驶的四维时空预训练算法driveworld。该方法采用世界模型进行预训练,设计记忆状态空间模型进行四维时空建模,通过预测场景的占据栅格,降低自动驾驶面临的随机不确定性和知识不确定性。该论文已被cvpr 2025接收。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文题目:DriveWorld: 4D Pre-trained Scene Understanding via World Models for Autonomous Driving
论文链接:https://www.php.cn/link/97f58cc60361f36cb40942c5c9a9e029
一、动机
自动驾驶的场景理解任务涉及到对场景的感知和预测未来变化等多个层面,这些层面不仅包括空间上的三维结构,还包含时间维度上的动态变化。这种复杂的场景理解要求模型能够捕捉和理解四维时空的内在关联,从而做出准确的决策。由于自然场景的随机性、环境的局部可观测性以及各种下游任务的多样性,学习四维时空表示是极具挑战性的。预训练在从大量数据中获取通用表示方面发挥着关键作用,能够构建一个具备通用知识的基础模型。然而,有关自动驾驶中四维时空的预训练研究仍然相对较少。
自动驾驶系统的设计和实现需要面对和处理各种不确定性,这些不确定性主要分为两类:Aleatoric不确定性和Epistemic不确定性。Aleatoric不确定性源自于世界的固有随机性,例如行人的突然移动或车辆的意外行为。Epistemic不确定性则源于对环境不完全的认知,例如由于遮挡或传感器限制导致的信息缺失。为了有效应对这些不确定性,自动驾驶系统必须能够利用过去的经验来预测未来可能的状态,并对不可见的区域进行推测。本工作通过四维时空预训练的世界模型来解决这一挑战,旨在提升自动驾驶系统在感知、预测和规划任务中的性能。
二、方法
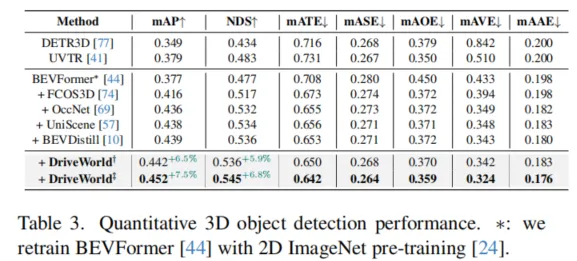
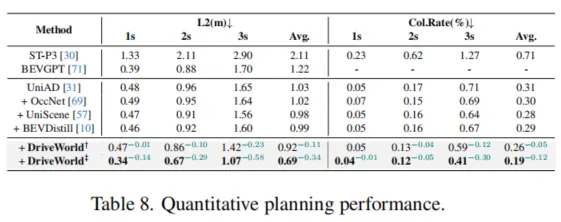
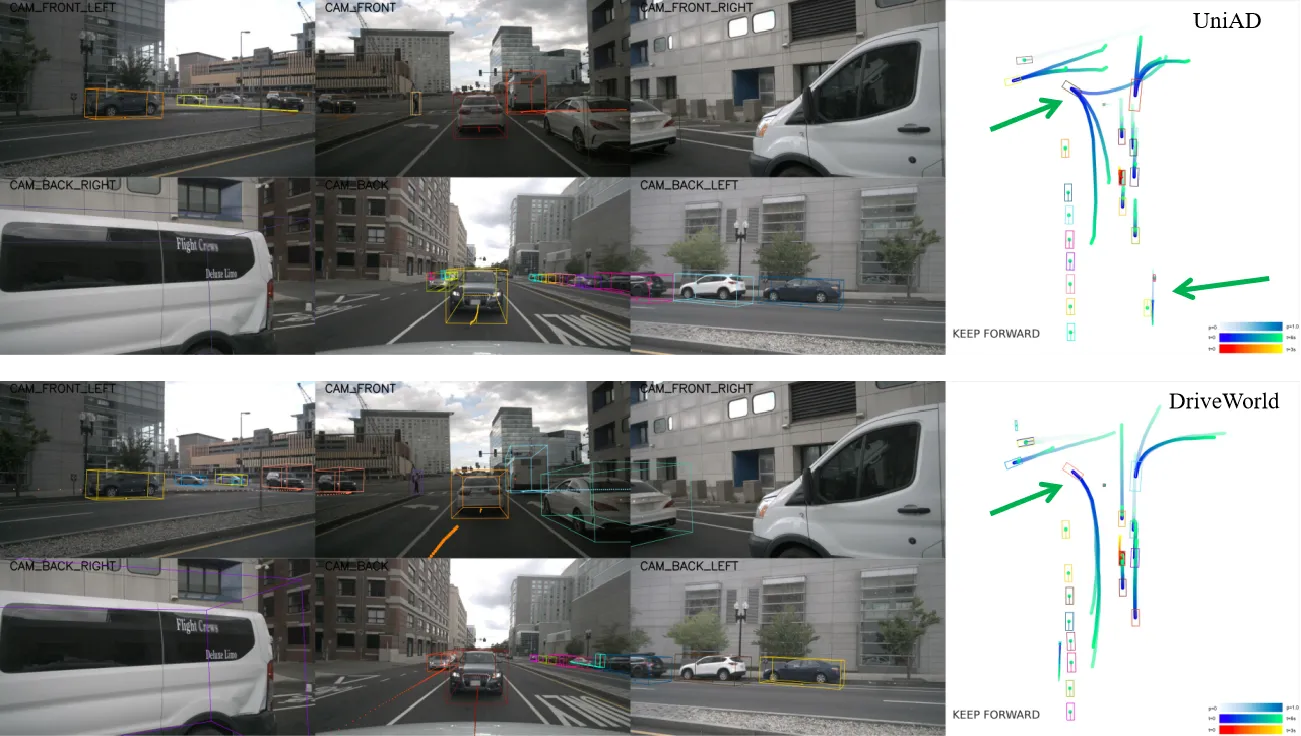
对于由自动驾驶环视相机系统观察到的T个视频帧的序列o1:T,以及它们对应的专家行为a1:T和三维占据栅格标签y1:T,其中三维占据栅格标签可以利用三维激光雷达点云和姿态数据获得。我们的目标是通过世界模型学习一个紧凑的BEV表示,该表示通过过去多视角图像和动作预测的当前和未来的三维占据栅格。
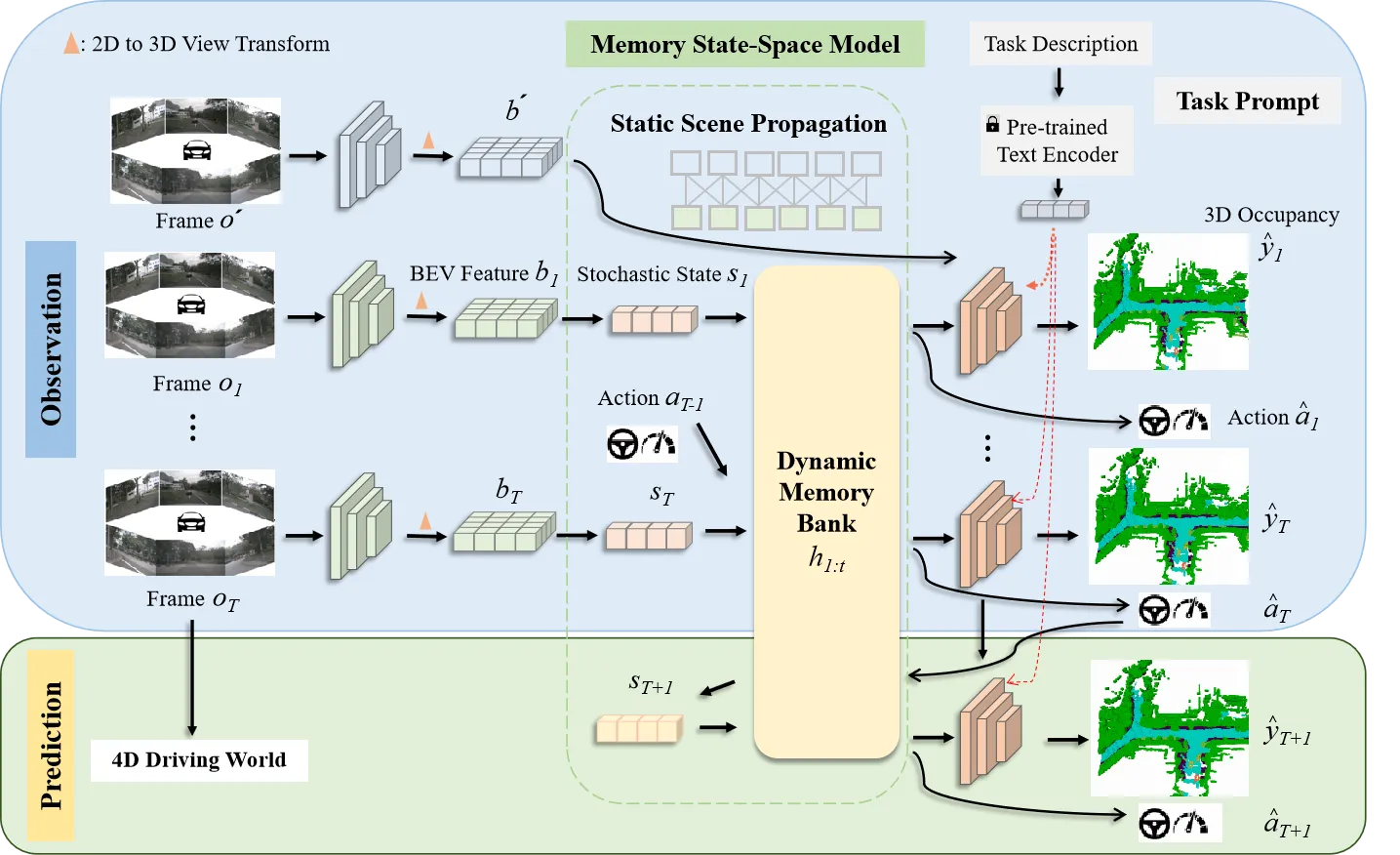
2.1时序概率模型
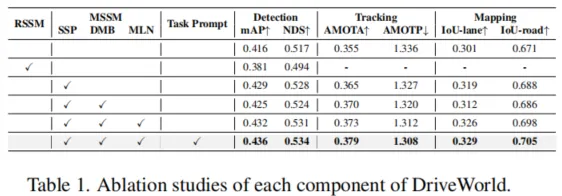
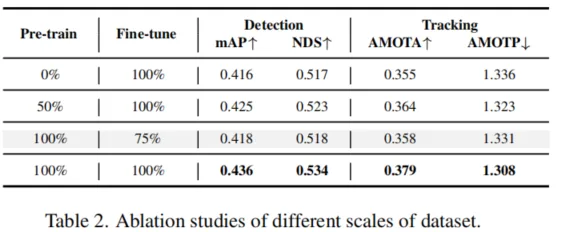
为了赋予模型四维时空建模的能力,我们首先引入两个潜在变量(h1:T,s1:T),其中ht表示历史信息变量,包含了到时间步t的所有历史信息,st表示随机状态变量,是模型预测未来状态的关键。ht通过历史信息h1:t−1和随机状态s1:t−1进行更新。为了预测未来状态,我们遵循循环状态空间模型(Recurrent State-Space Model,RSSM),构建后验状态分布q(st∣o≤t,a 考虑到BEV特征的维度很高,我们将其转换为一维向量xt,然后从(ht,at−1,xt)中抽样高斯分布以生成后验状态分布: 在没有观察到图像的情况下,模型根据历史信息和预测的动作得出先验状态分布: 2.1.1 动态信息传递 在自动驾驶的场景理解中,考虑物体的运动对于准确预测未来状态至关重要。为了捕捉这种动态信息,我们提出通过引入运动参数来建模物体的运动,从而在动态信息传播过程中实现运动感知。我们引入了运动感知层归一化(MLN)。运动属性包括速度v和相对时间间隔Δt。(v,Δt)被展平并通过两个线性层(ξ1,ξ2)转换为仿射向量γ和β:γ=ξ1(v,Δt),β=ξ2(v,Δt)。 然后执行仿射变换以得到运动感知的潜在随机状态,表示为st=γ⋅LN(st)+β。随着车辆的运动,确定性历史状态ht可以建立动态记忆库h1:t。通过与动态记忆库进行交叉注意机制计算,可以得到确定性历史状态ht。 2.1.2 空间信息传递 在自动驾驶的场景理解中,除了动态变化信息,空间结构信息同样重要。由于连续的场景帧通常只包含微小的变化,而场景的主要内容往往是由静态物体组成的,如道路、树木和交通标志,因此在处理这些信息时,直接将输入图像转换为一维向量可能会导致关键空间结构信息的丢失。我们从1到T帧中随机选择一帧o′,并使用其BEV特征b′构建一个描述空间感知结构的潜在静态表示b^=zθ(b′)。我们将空间感知的静态表示b^与动态变化的运动表示st结合起来,得到了周围场景的综合表示。 2.2 预训练辅助任务 对周围环境的全面理解对自动驾驶视至关重要的。我们提出将物理世界建模为三维占据栅格结构来描述车辆周围的环境。三维占据栅格解码器被设置为y^t=lθ(mθ(h~t,st),b^),其中mθ是将一维特征扩展到BEV维度的网络,lθ是用于预测占据栅格的三维卷积网络。这种四维占据栅格预训练不仅能够捕捉到场景的静态结构,还能够理解场景随时间的动态变化,为自动驾驶系统提供了更加丰富和动态的环境理解。 2.3 任务提示机制 虽然通过世界模型设计的预训练任务可以学习四维时空表示,但不同的下游任务关注的信息是不同的。为了缓解这个问题,受少样本图像识别的语义提示和多任务学习中的视觉示例引导提示的启发,引入了“任务提示”机制,为不同的任务提供特定的提示,以引导它们提取任务相关的特征。由于不同任务之间存在语义关联,我们利用大语言模型gφ(⋅)(例如BERT,CLIP)构建这些任务提示。例如,针对三维占据栅格重建任务的任务提示,其关注更多的是当前场景,设置为“任务是预测当前场景的三维占据栅格”。我们将提示ptext输入到gφ(⋅)中以获取提示编码gφ(ptext)。随后将其扩展到BEV的维度,表示为qφ(gφ(ptext)),将其与学到的时空特征集成在一起。 2.4 预训练目标函数 DriveWorld的预训练目标包括最小化后验状态分布与先验状态分布之间的差异(即Kullback-Leibler(KL)散度),以及最小化与过去和未来三维占据栅格(即交叉熵损失(CE))和动作(即L1损失)相关的损失。我们采用模型在T个时间步内观察输入,然后预测未来的三维占据栅格和L个步骤的动作。 三、实验 几秒钟去除图中不需要的元素 3.1 实验设置 我们在自动驾驶数据集上nuScenes和OpenScenes上进行预训练,并在nuScenes上进行微调。我们采用多帧激光雷达点云聚合的方式获得密集的三维占据栅格标签。 3.2 实验结果 这里展示部分结果,更多结果请参考论文。 四、总结 DriveWorld通过基于世界模型的四维时空预训练,提高自动驾驶系统对周围环境的理解和预测能力,降低自动驾驶面临的不确定性。DriveWorld提出了记忆状态空间模型进行时空建模,包含动态记忆存储模块用于学习时序感知表示,静态场景传播模块用于学习空间感知表示。为了进一步提升模型的适应性和灵活性,DriveWorld还引入了任务提示机制,允许模型根据当前的任务需求自适应地调整其表示,从而在不同的自动驾驶任务中实现最佳性能。 参考 [1]Chen Min, et al. Multi-Camera Unified Pre-Training Via 3D Scene Reconstruction[J]. IEEE Robotics and Automation Letters, 2025. [2]Chen Min, et al. Occupancy-mae: Self-supervised pre-training large-scale lidar point clouds with masked occupancy autoencoders[J]. IEEE Transactions on Intelligent Vehicles, 2025. EVOL创新团队介绍 赵健,中国电信人工智能研究院多媒体认知学习实验室(EVOL Lab)负责人、青年科学家,西北工业大学光电与智能研究院研究员、博导,博士毕业于新加坡国立大学,研究兴趣包括多媒体分析、临地安防、具身智能。 共发表CCF-A类论文60余篇,含一作T-PAMI×2(IF: 24.314)、IJCV×3(IF: 13.369),第一发明人授权国家发明专利5项。相关技术成果在百度、蚂蚁金服、奇虎360等6个科技行业领军企业得到应用,产生了显著效益。曾入选中国科协及北京市科协“青年人才托举工程”,主持国自然青年科学基金等项目6项。曾获吴文俊人工智能优秀青年奖(2025)、吴文俊人工智能自然科学奖一等奖(2/5,2025)、新加坡模式识别与机器智能协会(PREMIA)Lee Hwee Kuan奖、ACM Multimedia唯一最佳学生论文奖(一作,1/208,CCF-A类会议,2018),7次在国际重要科技赛事中夺冠。 担任北京图象图形学学会理事,国际知名期刊《Artificial Intelligence Advances》、《IET Computer Vision》编委,《Pattern Recognition Letters》、《Electronics》特刊客座编辑,VALSE资深领域主席,ACM Multimedia 2025分论坛主席,CICAI 2025/2025领域主席,CCBR 2025论坛主席,中国人工智能学会/中国图象图形学学会高级会员,“挑战杯”大学生科技作品竞赛评委,中国人工智能大赛专家委委员等。 GitHub主页:https://zhaoj9014.github.io 学院主页:https://www.php.cn/link/d0622bf20c3152d6c0d4335f537707ca 金磊,北京邮电大学特聘副研究 闵称,北京大学计算机学院博士,中科院计算所特别研究助理,主要研究方向包括自动驾驶、具身智能、三维重建,相关成果发表于CVPR、ICCV、ICRA、RAL等高水平会议与期刊,包括以第一作者发表CCF-A类会议CVPR,机器人顶级会议ICRA,机器*威期刊RAL等。参与多项国家重点研发项目。
p(st∣ht−1,st−1)∽N(μθ(ht,a^t−1),σθ(ht,a^t−1)I),
其中st被参数化为带有对角协方差的正态分布,初始分布设置为s1∽N(0,I)。(μϕ,σϕ)是参数化后验状态分布的多层感知机。
p(st∣ht−1,st−1)∽N(μθ(ht,a^t−1),σθ(ht,a^t−1)I),
其中(μθ,σθ)参数化先验状态分布。??是用于预测动作 a^t−1的策略网络,基于历史信息ht−1和随机状态st−1。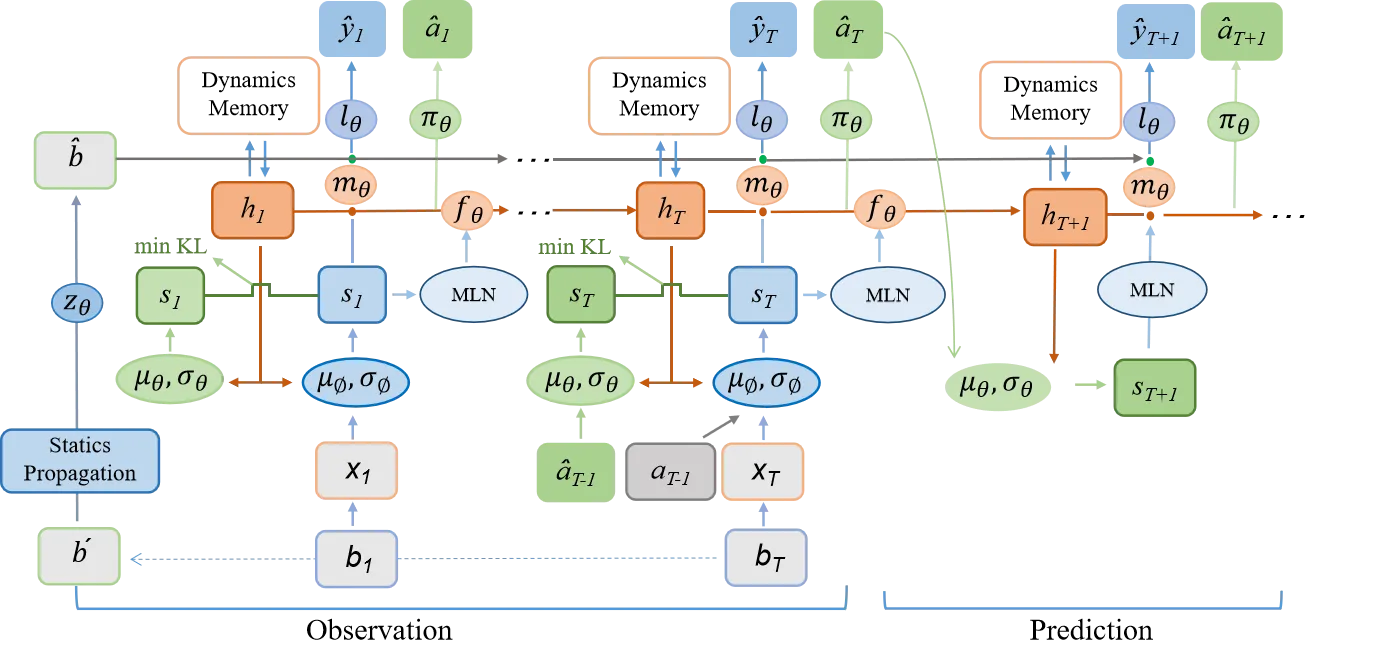
确定性历史状态为ht+1=fθ(ht,st)。 Remover
Remover
 304
查看详情
304
查看详情

 员,主要研究方向包括计算机视觉、数据挖掘、模式识别,其中深入研究人体姿态估计、人体动作识别、人体解析等细分领域,相关成果发表于CVPR, AAAI, NIPS, ACMMM等高水平会议及期刊,共发表SCI/EI索引论文40余篇,其中高水平论文11篇,包括以第一作者发表中科院JCR一区论文(IEEE Transactions on MultiMedia),CCF-A类会议CVPR, ACMMM论文,中科院JCR二区(Sensors, IEEE Sensor Journal)论文等。主持一项国家自然基金青年基金,参与两项国家重点研发项目以及四项自然基金面上项目。多次依托顶会组织ICCV2025/CVPR2025 workshop (Anti-U* Workshop & Challenge)。指导学生获得全国大学生物联网技术与应用“三创”大赛一等奖(北邮认定A类竞赛)。
员,主要研究方向包括计算机视觉、数据挖掘、模式识别,其中深入研究人体姿态估计、人体动作识别、人体解析等细分领域,相关成果发表于CVPR, AAAI, NIPS, ACMMM等高水平会议及期刊,共发表SCI/EI索引论文40余篇,其中高水平论文11篇,包括以第一作者发表中科院JCR一区论文(IEEE Transactions on MultiMedia),CCF-A类会议CVPR, ACMMM论文,中科院JCR二区(Sensors, IEEE Sensor Journal)论文等。主持一项国家自然基金青年基金,参与两项国家重点研发项目以及四项自然基金面上项目。多次依托顶会组织ICCV2025/CVPR2025 workshop (Anti-U* Workshop & Challenge)。指导学生获得全国大学生物联网技术与应用“三创”大赛一等奖(北邮认定A类竞赛)。
以上就是CVPR 2025 | 自动驾驶世界模型四维时空预训练的详细内容,更多请关注其它相关文章!
# 而在
# 黑龙江网站优化团队推荐
# 怎么在视频网站上推广
# 连锁药店营销推广报价
# seo优化和营销推广
# 嘉兴英文网站推广报价
# 佳木斯网站设计优化推广
# 网站建设周末兼职
# app推广营销环境分析
# 山东网站seo优化推广价格
# 百捷集团线上推广网站
# 中国科协
# 理论
# 新加坡
# 中国
# 北京
# 转换为
# 设置为
# 将其
# 未来
# 四维
# follow
# git
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
25个AI智能体源码现已公开,灵感来自斯坦福的「虚拟小镇」和《西部世界》
Transformer六周年:当年连NeurIPS Oral都没拿到,8位作者已创办数家AI独角兽
【搞事】时隔4年 谷歌更新安卓logo 机器人头更饱满了
苹果式 AI 哲学:不着一字,处处落子
QQ音乐业内率先推出「AI一起听」功能,领取你的AI听歌助手
微软向美国政府提供GPT大模型,如何保证安全性?
卫星通信牵引物联网竞争升维,模组厂商如何决胜百亿市场?
如何用AI开创智慧能源新时代?固德威正让能源“通人性”!
两小时就能超过人类!DeepMind最新AI速通26款雅达利游戏
AI无法对传统文化符号进行解构和创新
图灵奖得主Hinton:我已经老了,如何控制比人类更聪明的AI交给你们了
马斯克称未来机器人数量将多于人类,特斯拉愿共享自动驾驶技术
GPT-4 模型架构泄露:包含 1.8 万亿参数、采用混合专家模型
大模型训练成本降低近一半!新加坡国立大学最新优化器已投入使用
【趋势周报】全球元宇宙产业发展趋势:ChatGPT的出现,将元宇宙实现至少提前了10年
Meta 推出 Quest 超级分辨率技术,让 VR 画面更清晰
B站内测 AI 搜索功能,输入“?”即可体验
DeepMind用AI重写排序算法;将33B大模型塞进单个消费级GPU
陈根:AI冥想教练为用户提供个性化指导
生成式人工智能来了,如何保护未成年人? | 社会科学报
微软在德国举办MR研讨会,向女性分享元宇宙潜力
ChatGPT大更新!OpenAI奉上程序员大礼包:API新增杀手级能力还降价,新模型、四倍上下文都来了
AI行业盛会大咖云集!Sam Altam、“AI教父”......一文看懂最新观点
人工智能创作的“婴儿版超级英雄”,你觉得哪个最可爱
击败LLaMA?史上超强「猎鹰」排行存疑,符尧7行代码亲测,LeCun转赞
美军AI无人机“误杀”操作员,人工智能要在军事领域毁灭人类?
聚焦WAIC|AI技术支撑大模型探索未来
大模型新品出现井喷,AI产业迎来新时代
大厂出品!这个AI网站太顶了,所有功能免费用
联想首发AI PC于今年秋季,英特尔CEO确认AI PC时代来临
人工智能领域,突破难题:国产大模型“无源之水”问题得到解决。
英伟达H100霸榜权威AI性能测试 11分钟搞定基于GPT-3的大模型训练
提高开发效率:AmazonCodeWhisperer与Amazon Glue的集成和生成式AI的应用
百川智能发布Baichuan-13B AI模型,号称“130亿参数开源可商用”
北京市通用人工智能产业创新伙伴计划名单公布,京东科技入选“算力伙伴”
AI新视野,增长新势能,伙伴云受邀出席笔记侠创业讲真话AI峰会
谷歌内部正在测试代号为Genesis的AI新闻写作产品
定义人工智能的十个关键术语
OpenAI已向中国申请注册“GPT-5”商标,此前已在美国提交申请
掌阅科技对话式AI应用“阅爱聊”开启内测
AIGC 风潮刮到游戏产业,巨人网络与阿里云达成“游戏 +AI ”合作
小米又拿下国际比赛第一:AI翻译立功
这款在《自然通讯》发表的机器人,为变形金刚来到现实创造可能性
猿力科技入选北京市通用人工智能产业创新伙伴计划
AI大模型紫东太初已被注册商标 中科院已注册紫东太初大模型商标
视觉中国宣布推出AI灵感绘图、画面扩展功能
“直击”AI新世界,智能机器人再次“火出圈”了
学界业界大咖探讨:AI对数字艺术创新的推动力
优地网络助力新媒体拥抱人工智能时代
500元一张的AI艺术二维码制作,详细教程来了!
2024-08-07

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
