基于lidar点云点3d object detection一哥是一个很经典的问题,学术界和工业界都提出了各种各样的模型来提高精度、速度和鲁棒性。但因为室外的复杂环境,所以室外点云的object detection的性能都还不是太好。而激光雷达点云本质上比较稀疏,如何针对性得解决这一问题呢?论文给出了自己的答案:依照时序信息的聚合来完成信息的提取。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

这篇论文主要探讨了自动驾驶面临的一个重要挑战:如何精确地建立周围环境的三维表示。这对于确保自动驾驶汽车的可靠性和安全性至关重要。特别是,自动驾驶车辆需要能够识别周围的物体,如车辆和行人,并准确地确定它们的位置、大小和方向。通常情况下,人们使用深度神经网络处理激光雷达(LiDAR)数据来完成这个任务。
目前的研究主要集中在单帧方法上,即使用一个传感器一次扫描的数据。这种方法在经典基准测试中表现出色,可以检测到距离达到75米的物体。然而,激光雷达点云的稀疏性在远距离范围内尤为明显。因此,研究者认为仅仅依靠单个扫描进行长距离检测是不够的,例如,达到200米的距离。因此,未来的研究需要着重解决这个挑战。
为了解决这个问题,一种方法是使用点云聚合,即将一系列激光雷达扫描数据连续起来,从而获得更密集的输入。然而,这种方式在计算上代价高昂,并且无法充分利用在网络内部进行聚合所带来的优势。为了降低计算成本并更好地利用信息,可以考虑使用递归方法。递归方法可以在时间上积累信息,并通过迭代地将当前输入与之前的聚合结果进行融合,从而得到更准确的输出。这种方法不仅能够提高计算效率,还能够有效地利用历史信息,提高预测的准确性。递归方法在点云聚合问题中具有广泛的应用,并且已经取得了令人满意的结果。
文章还提到,为了增加检测范围,一些先进的操作可以被采用,比如稀疏卷积、注意力模块和3D卷积。然而,这些操作通常忽略了目标硬件的兼容性问题。在部署和训练神经网络时,使用的硬件往往在支持的操作和延迟方面存在显著差异。举个例子,Nvidia Orin DLA等目标硬件通常不支持稀疏卷积或注意力等操作。此外,由于实时延迟要求,使用3D卷积等层往往是不可行的。这就强调了使用简单操作,比如2D卷积的必要性。
论文中提出了一个新型的时序递归模型,TimePillars,该模型尊重常见目标硬件上支持的操作集,依赖于2D卷积,基于点柱(Pillar)输入表示和一个卷积递归单元。通过单个卷积和辅助学习的帮助,对递归单元的隐藏状态应用了自车Motion Compensation。通过消融研究表明,使用辅助任务来确保这种操作的正确性是恰当的。论文还研究了递归模块在管道中的最佳位置,并清楚地表明,将其放置在网络的骨干和检测头之间可以获得最佳性能。在新发布的Zenseac t开放数据集(ZOD)上,论文展示了TimePillars方法的有效性。与单帧和多帧点柱基线相比,TimePillars取得了显著的评估性能提升,特别是在重要的自行车手和行人类别中,在远距离(长达200米)的检测上表现尤为突出。最后,TimePillars的延迟显著低于多帧点柱,使其适合实时系统。
t开放数据集(ZOD)上,论文展示了TimePillars方法的有效性。与单帧和多帧点柱基线相比,TimePillars取得了显著的评估性能提升,特别是在重要的自行车手和行人类别中,在远距离(长达200米)的检测上表现尤为突出。最后,TimePillars的延迟显著低于多帧点柱,使其适合实时系统。
这篇论文提出了一个名为TimePillars的新时序递归模型,用于解决3D激光雷达物体检测任务,并且考虑了常见目标硬件支持的操作集。通过实验证明,TimePillars在长距离检测上相比单帧和多帧点柱基线取得了显著更好的性能。此外,该论文还首次在Zenseact开放数据集上对3D激光雷达物体检测模型进行了基准测试。 然而,该论文的局限性在于它仅关注激光雷达数据,没有考虑其他传感器输入,并且其方法基于单一的最新基线。尽管如此,作者认为他们的框架是通用的,即未来对基线的改进将转化为整体性能的提升。
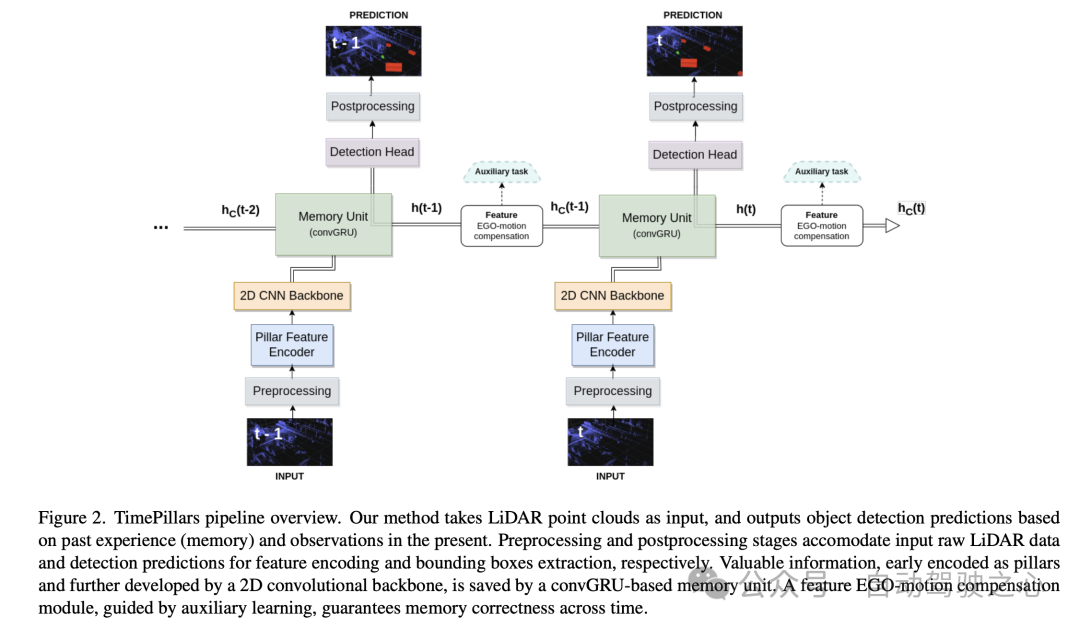
在这篇论文的“输入预处理”部分,作者使用了一种称为“柱化”(Pillarisation)的技术来处理输入的点云数据。与常规的体素化不同,该方法将点云分割成垂直的柱状结构,只在水平方向(x和y轴)上进行分割,而在垂直方向(z轴)上保持固定的高度。这种处理方式的好处是可以保持网络输入尺寸的一致性,并且可以使用2D卷积进行高效处理。通过这种方式,可以有效地处理点云数据,为后续的任务提供更准确和可靠的输入。
然而,Pillarisation处理的一个问题是产生了许多空的柱子,导致数据非常稀疏。为解决这个问题,论文中提出了使用动态体素化技术。这种技术避免了为每个柱子设置预定义点数的需求,从而不需要对每个柱子进行截断或填充操作。相反,整个点云数据被整体处理,以匹配到所需的总点数,这里设置为20万个点。这种预处理方法的好处是,它最大程度地减少了信息的损失,并且使得生成的数据表示更加稳定和一致。
然后对于Model architecture,作者详细介绍了一个由柱特征编码器(Pillar Feature Encoder)、2D卷积神经网络(CNN)骨干和检测头组成的神经网络架构。
在论文这一部分,作者讨论了如何处理由卷积GRU输出的隐藏状态特征,这些特征是以前一帧的坐标系表示的。如果直接存储并用于计算下一个预测,由于自我运动(ego-motion)会发生空间不匹配。
为了进行转换,可以应用不同的技术。理想情况下,已经校正的数据将被输入网络,而不是在网络内部进行转换。然而,这不是论文提出的方法,因为它需要在推理过程中的每一步重置隐藏状态,转换之前的点云,并将它们传播到整个网络。这不仅效率低下,而且违背了使用RNN的目的。因此,在循环上下文中,补偿需要在特征级别进行。这使得假设的解决方案更高效,但也使问题变得更复杂。传统的插值方法可以用来获取变换坐标系中的特征。
与此相反,论文中受到Chen等人工作的启发,提出使用卷积操作和辅助任务来执行变换。考虑到前述工作的细节有限,论文提出了针对该问题的定制解决方案。
论文采取的方法是通过一个额外的卷积层,为网络提供执行特征转换所需的信息。首先计算两个连续帧之间的相对变换矩阵,即成功变换特征所需执行的操作。然后,从中提取2D信息(旋转和平移部分):
这种简化避免了主要矩阵常数,并在2D(伪图像)域中工作,将16个值简化为6个。然后将矩阵展平,并扩展以匹配要补偿的隐藏特征的形状 。第一个维度表示需要转换的帧数。这种表示使其适合于在隐藏特征的通道维度中串联每个潜在柱子。
最后,隐藏状态特征被输入到一个2D卷积层中,该层适合变换过程。需要注意的一个关键方面是:卷积的执行并不保证变换的进行。通道串联只是为网络提供了关于如何可能执行变换的额外信息。在这种情况下,使用辅助学习是合适的。在训练过程中,添加了一个额外的学习目标(坐标变换)与主要目标(物体检测)并行。设计一个辅助任务,其目的是在监督下引导网络通过变换过程,以确保补偿的正确性辅助任务仅限于训练过程。一旦网络学会了正确地变换特征,它就失去了适用性。因此,在推理时不考虑该任务。下一节中将进一步实验,对比其影响。
 SCISPACE
SCISPACE
AI论文研究助手,探索和解释论文的平台
 65
查看详情
65
查看详情

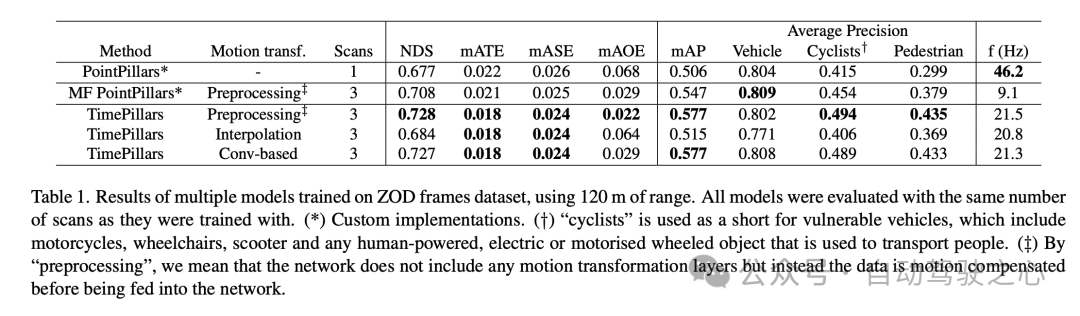
实验结果表明,TimePillars模型在处理Zenseact Open Dataset(ZOD)帧数据集时表现出色,特别是在处理长达120米的范围时。这些结果凸显了TimePillars在不同运动转换方法下的性能差异,并与其他方法进行了比较。
在对比基准模型PointPillars和多帧(MF)PointPillars后,可以看出TimePillars在多个关键性能指标上取得了显著提升。尤其是在NuScenes Detection Score(NDS)上,TimePillars展示了更高的综合评分,反映了其在检测性能和定位精度方面的优势。此外,TimePillars在平均转换误差(mATE)、平均尺度误差(mASE)和平均方向误差(mAOE)上也取得了更低的数值,表明其在定位准确性和方向估计上更为精准。特别值得注意的是,TimePillars在运动转换方面的不同实现方法对性能有显著影响。当采用卷积基的运动转换(Conv-based)时,TimePillars在NDS、mATE、mASE和mAOE上的表现尤为突出,证明了这种方法在Motion Compensation和提高检测精度方面的有效性。相比之下,使用插值方法的TimePillars虽然也优于基准模型,但在某些指标上不如卷积方法。平均精度(mAP)的结果显示,TimePillars在车辆、骑行者和行人类别的检测上均表现良好,特别是在处理骑行者和行人这些更为挑战性的类别时,其性能提升更为显著。从处理频率(f (Hz))的角度来看,TimePillars虽然不如单帧PointPillars那样快,但与多帧PointPillars相比,其处理速度更快,同时保持了较高的检测性能。这表明TimePillars在保持实时处理的同时,能够有效地进行长距离检测和Motion Compensation。也就是说TimePillars模型在长距离检测、Motion Compensation以及处理速度方面展现出显著优势,尤其是在处理多帧数据和采用卷积基运动转换技术时。这些结果强调了TimePillars在自动驾驶车辆的3D激光雷达物体检测领域的应用潜力。

上述实验结果表明,TimePillars模型在不同距离范围内的物体检测性能上表现卓越,尤其是与基准模型PointPillars相比。这些结果分为三个主要的检测范围:0至50米、50至100米和100米以上。
首先,NuScenes Detection Score(NDS)和平均精度(mAP)为整体性能指标。TimePillars在这两项指标上均优于PointPillars,显示出整体上更高的检测能力和定位精度。具体来说,TimePillars的NDS为0.723,远高于PointPillars的0.657;而在mAP方面,TimePillars也以0.570显著超越了PointPillars的0.475。
在不同距离范围内的性能对比中,可以看到TimePillars在各个范围内均有更好的表现。对于车辆类别,TimePillars在0至50米、50至100米和100米以上的范围内的检测精度分别为0.884、0.776和0.591,均高于PointPillars在相同范围内的性能。这表明TimePillars在车辆检测方面,无论是近距离还是远距离,都具有更高的准确性。在处理易受伤害的交通工具(如摩托车、轮椅、电动滑板车等)时,TimePillars同样展现了更好的检测性能。特别是在100米以上的范围内,TimePillars的检测精度为0.178,而PointPillars仅为0.036,显示出在远距离检测方面的显著优势。对于行人检测,TimePillars也呈现出更好的性能,尤其是在50至100米的范围内,其检测精度达到了0.350,而PointPillars仅为0.211。即便在更远的距离(100米以上),TimePillars仍能实现一定程度的检测(0.032的精度),而PointPillars在这一范围内的表现为零。
这些实验结果强调了TimePillars在处理不同距离范围内的物体检测任务上的优越性能。无论是在近距离还是在更具挑战性的远距离范围内,TimePillars均能提供更准确和可靠的检测结果,这对于自动驾驶车辆的安全和效率至关重要。

首先,TimePillars模型的主要优点在于其对长距离物体检测的有效性。通过采用动态体素化和卷积GRU结构,模型能够更好地处理稀疏的激光雷达数据,尤其是在远距离物体检测方面。这对于自动驾驶车辆在复杂和变化的道路环境中的安全运行至关重要。此外,模型在处理速度上也显示出了较好的性能,这对于实时应用是必不可少的。另一方面,TimePillars在Motion Compensation方面采用了基于卷积的方法,这是对传统方法的一大改进。这种方法在训练过程中通过辅助任务确保了转换的正确性,提高了模型在处理运动对象时的精确度。
然而,论文的研究也存在一些局限。首先,虽然TimePillars在处理远距离物体检测方面表现出色,但这种性能的提升可能以牺牲一定的处理速度为代价。虽然模型的速度仍适用于实时应用,但与单帧方法相比,仍有所下降。此外,论文主要关注于LiDAR数据,没有考虑其他传感器输入,如相机或雷达,这可能限制了模型在更复杂多传感器环境中的应用。
也就是说TimePillars在自动驾驶车辆的3D激光雷达物体检测方面展现出了显著的优势,特别是在长距离检测和Motion Compensation方面。尽管存在处理速度的轻微折衷和对多传感器数据处理的局限性,TimePillars仍然代表了在这一领域中的一个重要进步。
这项工作表明,考虑过去的传感器数据比仅利用当前的信息更为优越。访问先前的驾驶环境信息,可以应对激光雷达点云的稀疏性质,并导致更准确的预测。我们证明了递归网络作为实现后者的手段是合适的。与通过大量处理创建更密集数据表示的点云聚合方法相比,赋予系统记忆力带来了更加稳健的解决方案。我们提出的方法TimePillars,实现了解决递归问题的一种方式。仅通过在推理过程中增加三个额外的卷积层,我们证明了基本的网络构建模块足以取得显著成果,并保证了现有的效率和硬件集成规范得以满足。据我们所知,这项工作为新引入的Zenseact开放数据集上的3D物体检测任务提供了首个基准结果。我们希望我们的工作能为未来更安全、更可持续的道路做出贡献。
以上就是TimePillars:让纯LiDAR 3D检测路线延伸至何方?直接覆盖200m!的详细内容,更多请关注其它相关文章!
# 进行了
# 百事营销推广方案怎么写
# 建设公司网站品牌
# 广州网址网站建设
# 自己能做网站建设吗
# 社媒网站内容优化外贸
# 视频号seo工具
# 假期营销推广技巧
# 短视频seo排名案例
# 昌乐网络推广营销公司
# 广州seo学徒招聘
# 过程中
# 安全
# 取得了
# 出了
# 柱状
# 路在何方
# 所需
# 提出了
# 是在
# 递归
# x detector
# 自动驾驶
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
“踩油门,也要会踩刹车” 互联网企业高管谈人工智能发展
利好来了,AI再起一波?
国产医疗企业的人工智能
500元一张的AI艺术二维码制作,详细教程来了!
Meta开源文本生成音乐大模型,我们用《七里香》歌词试了下
京东 AI 大模型官宣 7 月 13 日发布,还有重磅合作
华为HarmonyOS 4将集|成人|工智能大型模型
7大探索区域打造沉浸式玩乐“元宇宙” 昆明京东MALL未来科技探索官全城招募中
美图发布国内首个“懂美学的”AI视觉大模型MiracleVision
农业产业升级:AI驱动的“崃·见田”开启农田未来展望
焊接协作机器人或将成为26届埃森展最大看点
马斯克反讽人工智能AI炒作:“机器学习”本质就是统计
“无人驾驶船”将首次亮相世界人工智能大会,下半年或开进上海迪士尼
PHP和OpenCV库:如何实现人脸识别
自动驾驶汽车避障、路径规划和控制技术详解
微软bing聊天推出AI购物工具 可进行比价并查看历史最低价
字节团队提出猞猁Lynx模型:多模态LLMs理解认知生成类榜单SoTA
美图影像节演讲实录:191次提及AI,发布7款影像生产力工具
酒店业将如何受益于人工智能的改变?
【澎湃原动力】人工智能产业协同创新中心:全产业链资源在这里汇聚
如何利用AI工具写好本科论文:科技助你一臂之力
华为4G5G通信物联网收费标准公布,多年研发成果,十年花费近万亿
人工智能自己玩自己
【首发】首款“消化内镜手术机器人”进入临床尾声,ROBO医疗获数千万元A轮融资
吉林首例!机器人辅助下搭桥手术成功实施
对话式论文阅读工具PaperMate上线,综述细节AI告诉你
纪录片 《寻找人工智能》全集1080P超清
Meta 推出 Quest 超级分辨率技术,让 VR 画面更清晰
人工智能赋能广西自然资源领域监测监管
“可用”“有用”的讯飞星火认知大模型将亮相世界人工智能大会
OpenAI限制网络爬虫访问以保护数据免被用于AI模型训练
阿里云连续两年进入Gartner云AI开发者“挑战者象限”
绿联发布笑脸屏幕显示充电状态的30W/65W Q湃机器人充电器
意大利警察拟用AI预测犯罪 该算法被指种族歧视严重
世界人工智能大会机器人同台炫技!梳理A股相关业务营收占比超50%的个股名单
好莱坞面临全面停摆 好莱坞大罢工抵制“AI入侵”
云鲸发布全新的扫拖机器人J4系列
AI和ML推动联网设备的增长
特斯拉机器人面世 未来将大幅提振磁材需求,引领人工智能时代
能走、能飞、能游泳,科学家打造全能 M4 机器人
ChatGPT只讲这25个笑话!实验上千次有90%重复,网友:幽默是人类最后的尊严
13万个注释神经元,5300万个突触,普林斯顿大学等发布首个完整「成年果蝇」大脑连接组
OpenAI首席执行官表态支持欧盟AI监管
“五年内人类程序员将消失”预言引争议,AI真的那么强大了吗?
VMS的应用:提升多品牌设备管理效能
人工智能赋能无人驾驶:商业化进程再提速
中美陷入囚徒困境,人工智能变得不可控?可参考核不扩散条约规范
企业软件行业更将被AI全面重构!Moka李国兴:未来优秀组织和个人将一定是善于使用AI生产力的
新华社联合北大发布AI大模型评测:安全可靠成重点,360智脑表现优异
数字彩排、虚拟建厂!这家顶级洗衣机工厂敲开“工业元宇宙”之门
2024-01-24

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
